自己紹介
モノグサのソフトウェアエンジニアインターンに参加した北村祐稀です。普段は大阪大学で情報科学教育の教材研究に取り組んでいます。
取り組んだこと
先日社内の成果発表会がありました。その際に使用したスライドの抜粋に沿って、今回のインターンで取り組んだことを紹介します。

今回のインターンでは「日本語誤答生成の改善」というタスクに取り組みました。
Monoxer はいくつかの種類の問題形式に対応しており、その 1 つに「ペアエントリ」があります。
この形式では「apple - りんご」のような憶えたいペアを登録することで、自動で問題が生成されます。
Q.「apple は次のうちどれか?」
選択肢.「りんご」「ぶどう」「みかん」「もも」
といった感じです。
ここでは「apple - りんご」という情報から「ぶどう」「みかん」「もも」という誤答を生成しなければなりません。
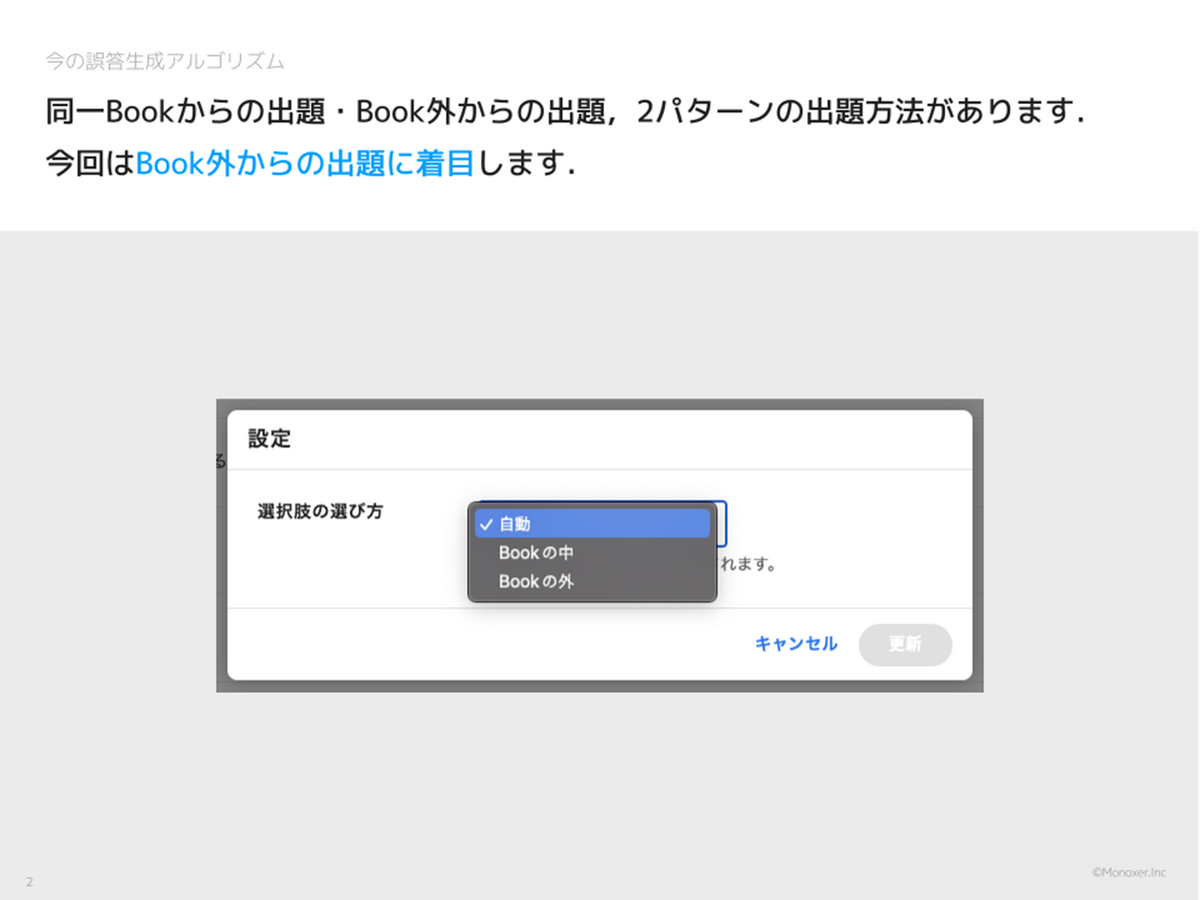
では、現在の Monoxer ではどのようにして日本語の誤答を生成しているのでしょうか? まず大まかに、Book 内からの出題と Book 外からの出題の 2 パターンの出題方法があります。
Book 内からの出題では、同じ Book に「rain - 雨」「walk - 歩く」「beautiful - 美しい」というペアエントリが登録されていたら「apple は次のうちどれか?」「りんご」「雨」「歩く」「美しい」といったように誤答を生成します。
Book 外からの出題方法は次のスライドで説明します。Monoxer の設定画面から「Book の中」「Book の外」「自動 (Book の中と外の両方から出題)」を選べるようになっています。今回のインターンでは「Book の外」からの出題に着目しました。

Book 外での誤答生成方法はいくつかの種類が組み合わさってできています。スライドには主な方法を 3 つ挙げました。理科・社会でよく使う単語がたくさん登録されたデータベースを使う方法、Trie 木というデータ構造を使う方法などがあります。
今回着目したのは Word2Vec を使う方法です。Word2Vec を使えば、入力された単語と類似した意味を持つ単語を類似度の順番で取得できます。「りんご」を入力として与えれば、「ぶどう」「みかん」「もも」といった出力が得られるでしょう。

ここまで、現在使用されている誤答生成の方法を紹介してきましたが、あまり良くない誤答が生成されてしまうこともあります。ここでは生成される誤答を「紛らわしい誤答」「不自然な誤答」「質の良い誤答」の 3 種類に分けて考えてみます。
まずは「紛らわしい誤答」です。「challenge」という問題に対して「難問」「難題」という選択肢が表示されていますが、これはどちらが正解なのでしょうか? 正解と誤答選択肢の意味が近すぎて区別がつかなくなってしまっています。
次は「不自然な誤答」です。「claim - 主張する」というペアエントリに対して「見解する」「唱えし」「反論し」という誤答が生成されていますが、「見解する」という言葉は存在しませんし、「唱えし」「反論し」は中途半端です。こういった不自然な選択肢を排除すると、「claim」の意味を憶えていなくても消去法で「主張する」が選べてしまいます。
今回は「紛らわしい誤答」「不自然な誤答」以外を「質の良い誤答」と呼ぶことにしました。インターンの課題は「質の良い誤答」だけが出題されるようにすることにしました。

ここからは実際に実現している最中のアイデアを紹介します。まずは「不自然な誤答」の対策です。
例えば「claim - 主張する」というペアエントリに対し「主張し」という「不自然な誤答」が生成されてしまうことがありました。これは形態素解析によって「主張する」を「主張 + する」と単語の列に分解し、そのうち「する」と類似した単語である「し」を Word2Vec で取得し、「主張 + し」を連結して「主張し」という誤答選択肢を生成する、という流れでできています。このケースが不自然になってしまったのは、動詞の終止形である「する」が動詞の連用形である「し」に置き換わってしまっていることだと考えました。
他方、「claim - 主張する」というペアエントリに対し「反論する」という「適切な誤答」が生成されることもあります。これは形態素解析によって「主張する」を「主張 + する」と単語の列に分解し、そのうち「主張」と類似した単語である「反論」を Word2Vec で取得し、「反論 + する」を連結して「主張し」という誤答選択肢を生成する、という流れでできています。このケースが自然なままなのは、名詞が名詞に置き換わっているからだと考えました。
つまり、置き換えの際に品詞と活用が同じになる場合だけ採用するようにすれば「不自然な誤答」を減らすことができそうです。
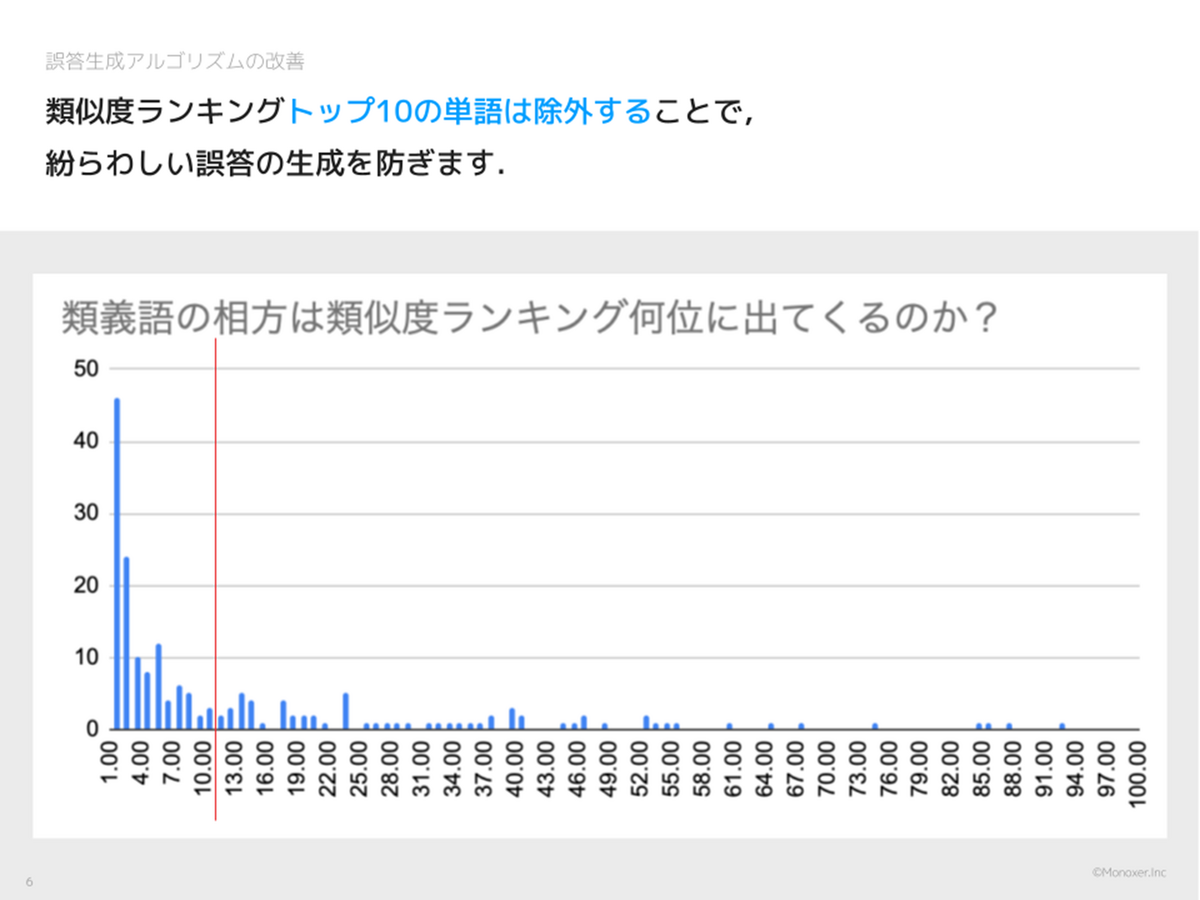
今度は「紛らわしい誤答」を減らすためのアイデアです。とある類義語のデータを用いて調査を行ったところ、Word2Vec に類義語の片方を入力すると、その相方が 10 位までに出現するケースが 64 % ほどであるとわかりました。そこで、Word2Vec の出力の 10 位までを捨てて 11 位からを使うようにすることで「紛らわしい誤答」を減らせそうです。
ちなみに類似度のスコアを使って「類似度が 0.8 以上は捨てる」といった案もあったのですが、こちらは不採用にしました。Word2Vec の類似度は文脈に基づいているのですが、様々な文脈で使用される一般的な語は総じてスコアが低くなりやすいのに対し、専門用語などは意味が異なっていてもスコアが高くなりやすいからです。
ここで紹介した改善方法も紹介できなかった改善方法も今後リリース予定ですので、Monoxer を利用されている方はぜひご期待ください!
インターンの感想
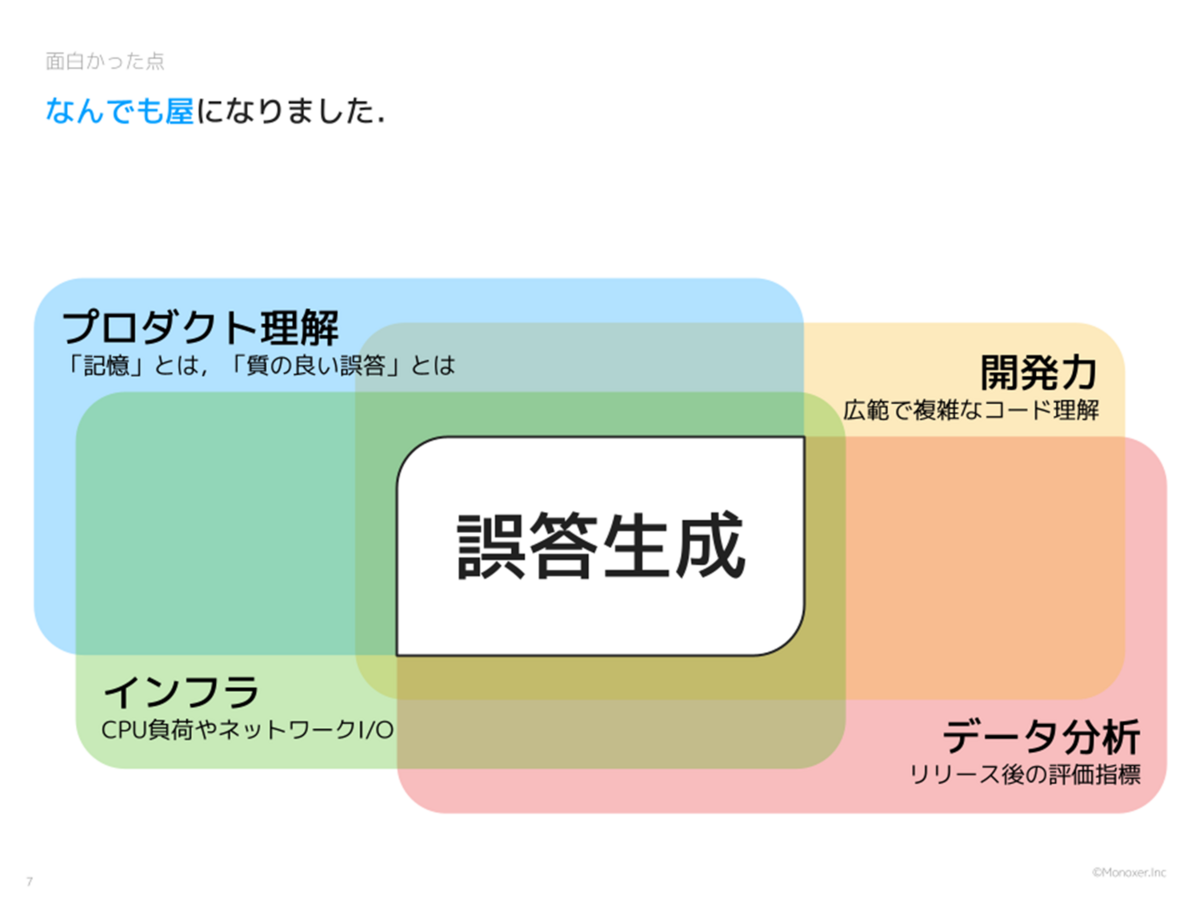
今回のインターンでは本当に幅広い範囲を扱わせていただきました。
まずは「プロダクト理解」です。そもそも「質の良い誤答」とは何なのか、突き詰めていけば Monoxer の本質である「記憶」とは何なのか、自分で考えたり複数の社員の方と相談したりしながら考えを固めていきました。
次に「開発力」「インフラ」です。前述の通り誤答生成はいくつかの手法を組み合わせて実現されているため、コードも複雑になっています。Monoxer の肝で一日に何百万回も呼び出されるため、負荷の懸念もあります。丁寧な理解や設計が求められます。
そして「データ分析」です。改善のアイデアを検討する中で Monoxer の学習ログデータを用いて仮説検証を行いました。リリース後も確実に良い影響が出ているかモニタリングするため事後評価を予定しています。Monoxer が蓄積する複雑で大量のビッグデータを可視化していきました。
こういった様々なスキルが総合的に試されるのが「誤答生成」という領域なのです。難しい課題にチャレンジさせていただき、強力な経験を積ませていただきました。ありがとうございました。