
自己紹介
こんにちは。モノグサのソフトウェアエンジニアのインターンに参加した堤歩斗です。普段は東京都立大学でコンピュータサイエンスの学習をしています。モノグサでは1ヶ月半ほどインターンをしていました。 この記事ではインターンを振り返りモノグサで取り組んだことやインターン中のあれこれについて紹介したいと思います。
参加を決めた理由
モノグサを知ったのはICPC2022アジア横浜地区大会のスポンサーブースでお話を聞いたときでした。その他にもAtCoder上でモノグサプログラミングコンテストを開催していたり、CodeQUEENのスポンサーを務めるなど、モノグサは競技プログラミングに理解のある会社なのだなという印象を持っていました。 私は比較的長い期間で本格的な開発に携われるインターンに行ってみたいと思っていました。 そんな中、モノグサの春インターンを見つけました。モノグサのインターンは期間が1ヶ月以上と希望にマッチしており、大学の春休み期間に取り組むのにちょうど良いと思いました。さらに、応募の決め手となったのはAtCoderJobsでの要求ランクがC(AtCoderのレートが緑)でちょうど応募可能だったためです。競技プログラミングで得た機会を生かしてみようと思い応募しました。
取り組んだこと
色々なことに取り組みました。最初はiOSとAndroidのアプリ開発に触れました。そして最後にはwebフロントエンドからバックエンドの開発まで、幅広くフルスタックでの開発を体験できました。そんな中から今回はインターン中にメインで取り組んだテーマについて紹介します。
Monoxerでは、「文章記憶機能」を提供しています。文章記憶機能というのは以下のような機能で、
- 試験勉強に必要な文章や歴史的に有名な詩、業務に必要なマニュアルやトークスクリプトなど、様々なシーンで記憶が必要な文章が存在しています。
- モノグサでは、この「ミラーの法則」を参考にして、文章をチャンク(情報のかたまり)に分割したうえで、チャンクごとの記憶を促すための出題する機能を開発いたしました。
引用元:文章をチャンクに分割して記憶する「文章記憶機能」をリリース | Monoxer・解いて憶える記憶アプリ
今回私は文章記憶機能における問題作成時のチェックプロセスを自動化するツールの開発を行いました。
文章記憶機能では、覚えたい元の文章を分割することで問題を作成します。 今回自動化したいチェックプロセスというのは、元の文章を分割して出来た短い文章のブロック(図1のL1に相当)同士で類似したものがないかをチェックするというものです。
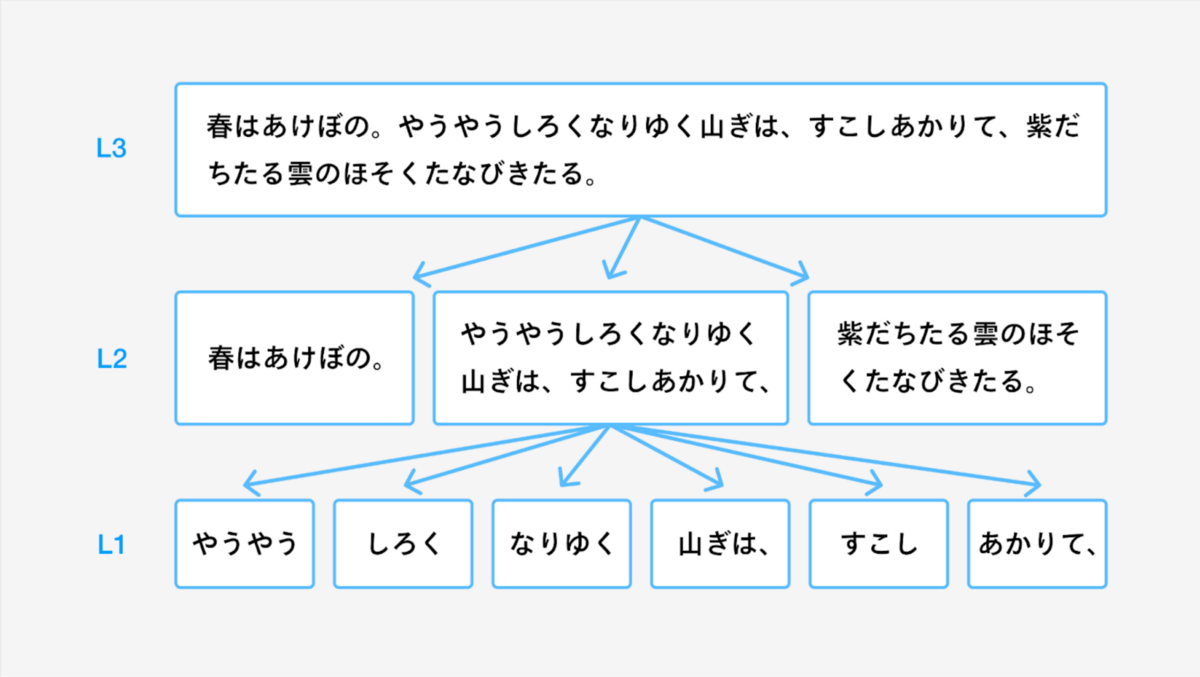
なぜ、このようなチェックをする必要があったのでしょうか?それは類似したものがあった場合に問題の選択肢にそれらが同時に出現することがあるからです。(図2 似たような選択肢が出現するスクリーンショット)
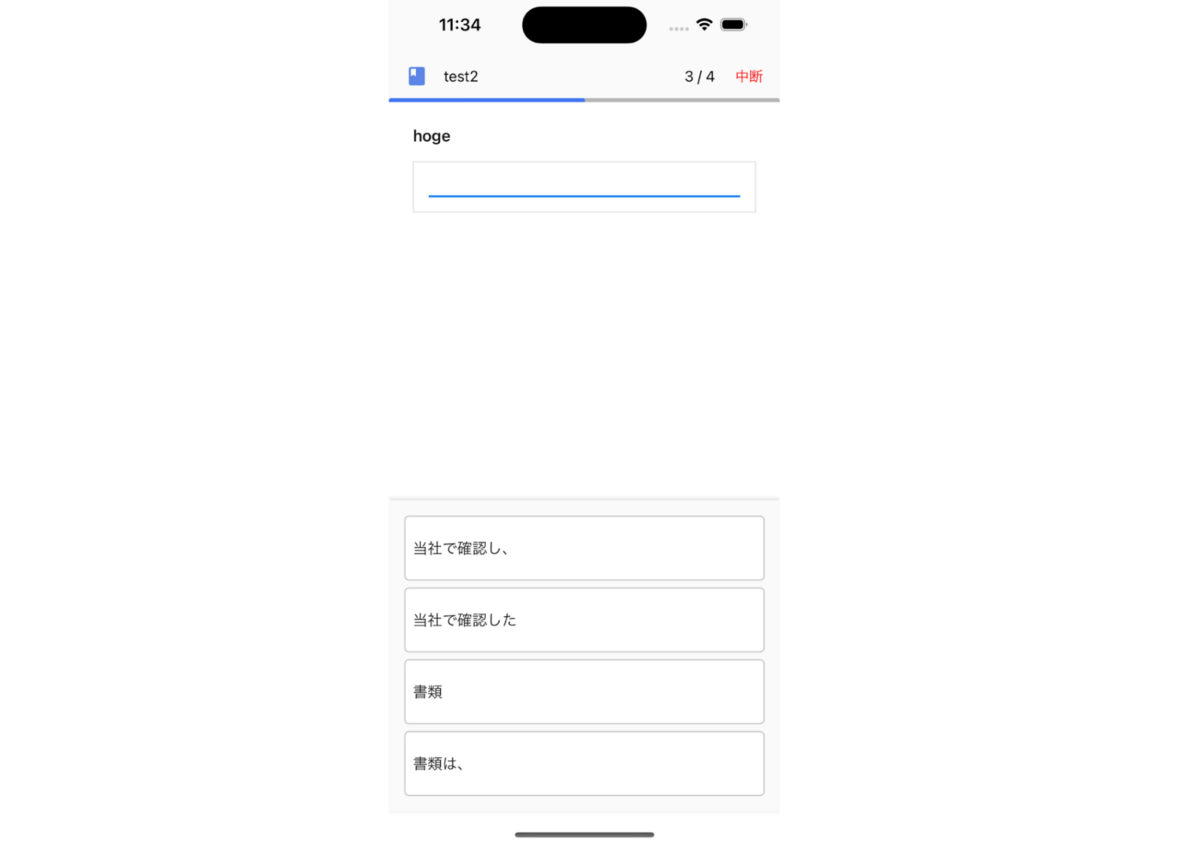
このスクリーンショットでは「当社で確認し、」と「当社で確認した」という選択肢が同時に出現しています。この問題の正解は「当社で確認した」なのですが、「当社で確認し、」を選択しても良いように思えます。 このように似たような選択肢が出現すると、文章の内容を十分に記憶出来ているのに誤答と判定されてしまうという問題が発生します。
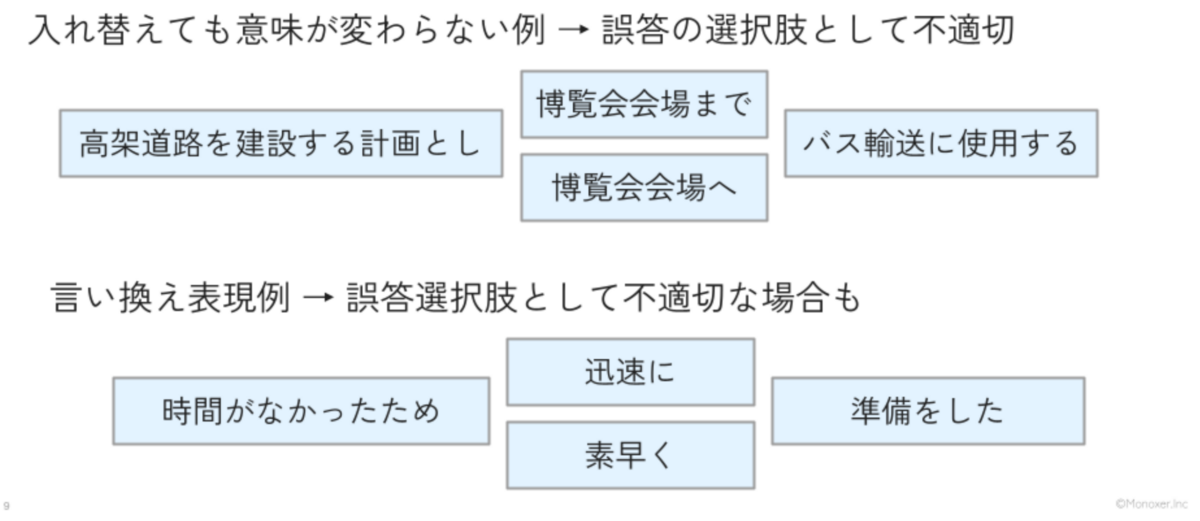
今回のケースではスクリーンショット中の「当社で確認し、」と「当社で確認した」のような表記揺れや文末の表現の違いがある文章を検出するだけでなく、「迅速に」と「素早く」といったような言い換え表現も検出したいという背景がありました。(図3 検出したい文章の例)
そこで、このチェックを自動で行うために、SentenceTransformerという自然言語処理ライブラリを用いました。
SentenceTransformerは、文などのテキストデータをベクトル表現に変換するためのライブラリです。SentenceTransformerのモデルは、文を入力として受け取り、固定長のベクトルにエンコードします。このベクトル表現を用いることで、文間の類似度を計算することが可能になります。すなわち、SentenceTransformerを用いると文レベルでの意味論的な情報を捉えることが出来ます。 *1
実際には単純にSentenceTransformerで文章の最小単位(図1のL1に相当)同士の類似度を計算するだけではなく、その文章を誤って選んだ場合にどうなるか?という部分を加味して判定するようにしました。具体的には、「正解の選択肢を選んだ場合に完成する元の文章」と「類似した誤答選択肢を選んだ場合に完成する類似した文章」の二つの類似度を計算することで、誤答選択肢として適切かどうかをより正確に判定できるようになりました。
また、このツールの使用者はエンジニアではなく社内のコンテンツを作成する方々になります。そのため、普段のコンテンツ作成で使用しているGoogle スプレッドシートからGUIでの操作が出来るようにしました。そこで、以下の2つを開発しました。
- 類似度の計算処理等を実行するバックエンドAPI
- APIを叩き、結果を視覚的に表示するGoogle スプレッドシートのアドオン
また、SentenceTransformerを使用するには、Pythonで提供されているライブラリを利用する必要があります。そのため、Pythonの実行環境が必要です。そこで今回はGCPのCloud Runへ新たにデプロイすることになりました。
Cloud Runはコンテナを直接実行できるマネージドな実行環境で、リクエストベースでの自動スケーリングが行われます。すなわち、リクエストがあった場合にのみ動作し、しばらくリクエストが無い場合にはスケールダウンされるということです。今回作成したいツールはコンスタントにリクエストがあるものではなく、コンテンツ作成の作業時という限られたタイミングでのみ使用できれば良いので、Cloud Runは最適な選択肢でした。さらに、Cloud Runではコンテナを直接実行できるので、実行環境の新規構築としては比較的簡単です。 *2
今回はインフラチームの方と連携しながら、必要な知識を学びつつ、Cloud Runのデプロイにかかるプロセスを習得しました。この過程で、Cloud Runの仕組み、コンテナ技術、GCPの基本操作など、クラウドインフラに関する幅広い知識が得られました。
また、SentenceTransformerを使用するに当たり、パフォーマンスと精度についても課題がありました。デプロイにおいては、これら二つの要素を最適化することが重要な挑戦となりました。応答時間と消費するリソースの改善を精度を犠牲にすることなく、実現する必要があります。そのために、モデルの軽量化やキャッシュの利用などを施しました。このプロセスを通じて、パフォーマンスと精度の間のバランスを取ることの難しさを学びました。
インターンの感想
今回のインターンでは本当に幅広い領域を扱わせていただきました。「どんな文章を検出するべきなのか」というプロダクト理解から、「デプロイやシステム構成」といったインフラ領域、さらにバックエンドとフロントエンドの一通りの実装などに取り組みました。その中で自分で考えた内容に対して様々な方面からレビューをいただき、一つの機能を完成させていくという一連のプロセスが体験できました。主体性を持って幅広い領域の開発を経験できたことは非常に興味深かったです。
さらに、本格的なコードレビューを受けてプロダクトに自身のPullRequestをマージするという経験は学生にはなかなか得られるものではなく、様々な学びがありました。また、PullRequestだけでなく、Design Docという開発にまつわる文書のレビューも社内から広く受けられるモノグサの文化に感心しました。
そして、モノグサでは非常に働きやすい環境が整っているなとも感じました。インターンの最初に支給されるPCのキーボード配列の希望調査があったときから、インターンを終える今日まで、社員のことを第一に考えていることを随所に感じました。
このインターン体験を通じて、幅広いスキルを身につけることができました。また、実務でのコードレビューやプロダクト開発の一端を担うなど、貴重な経験をさせていただき、成長できたと自負しています。技術的なスキルだけでなく、チームで働く重要性や、プロダクト開発の過程における細かな配慮を学ぶ機会もありました。最後に、この機会を提供してくださったモノグサの皆様に心から感謝を申し上げます。ありがとうございました。