自己紹介
はじめまして。モノグサ株式会社でソフトウェアエンジニアのインターンとして働いている大森です。モノグサには2022年の春にインターンとして参加させていただき、その後も通年でインターンを継続しています。この記事では春のインターンで取り組んだ課題についてその概要を紹介したいと思います。
参加を決めた理由
Atcoderという競技プログラミングのサイトで求人を見かけ、プロダクト開発に関して科学的な態度を強調していた点に惹かれました。また、ボードゲームが好きだった私にとって、その文化が社内にあるということも魅力的なポイントでした。
取り組んだこと
モノグサアプリでは、数式が答えになる数学の問題をサポートしています。これまでの回答方法は数式が入力できるオリジナルなキーボードを利用したものでした。

しかし、この入力方式は分数や指数などの構造を入力しようとするのが複雑だったりと、利便性に問題を抱えている状況でした。そこで、最も明快な入力方式として、手書きされた数式を認識して回答に用いるという案が登場しました。最終的に、次のような形で実現されました。
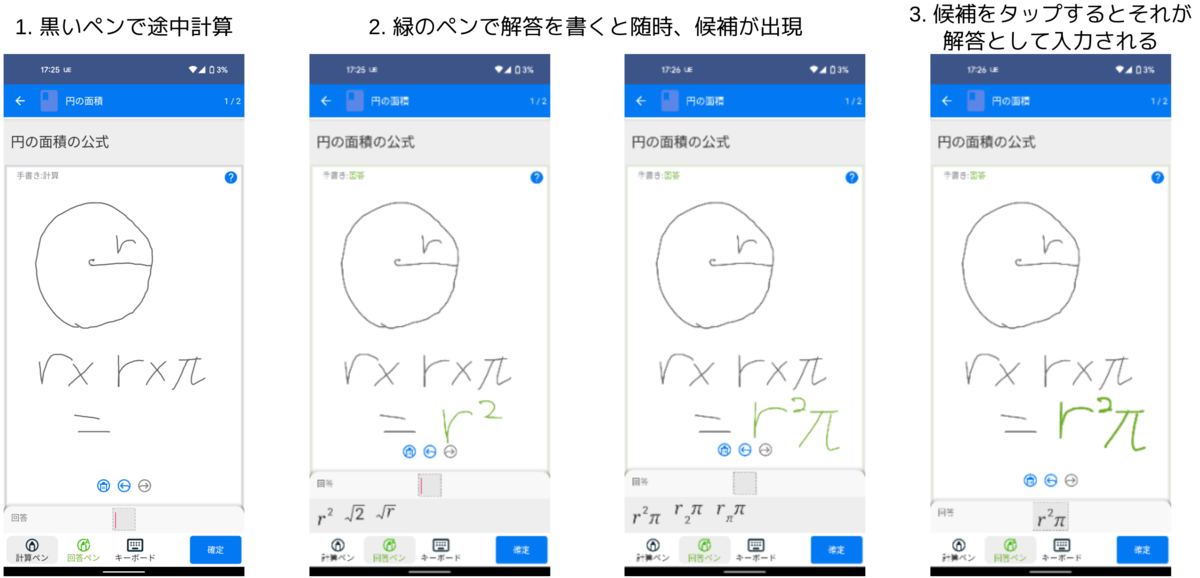
また、認識された解答を既存機能のキーボードで修正、最初からキーボードで入力することも可能です。
現在の手書き数式認識タスク(Handwritten Mathematical Formula Recognition)の研究現場をみてみると、最近のものはEnd-to-endで深層学習に任せるタイプのものも多いようです。そのうちの一つに
github.com
として実装が公開されているものがあったため、このリポジトリのコードを元にして考えることにしました(以下 、BTTR と呼びます)。
「オフラインでも使用可能にしたい」、「導入が手軽」といった理由から推論はモバイル上(iOS, android)で行うことになりました。BTTRはPyTorchによる実装で、android上で動かすための手引きが公式に存在しており、実際に端末上で手書き数式認識を動作させることは思いのほか容易でした。
pytorch.org
この時点での動作イメージは次の通りです。
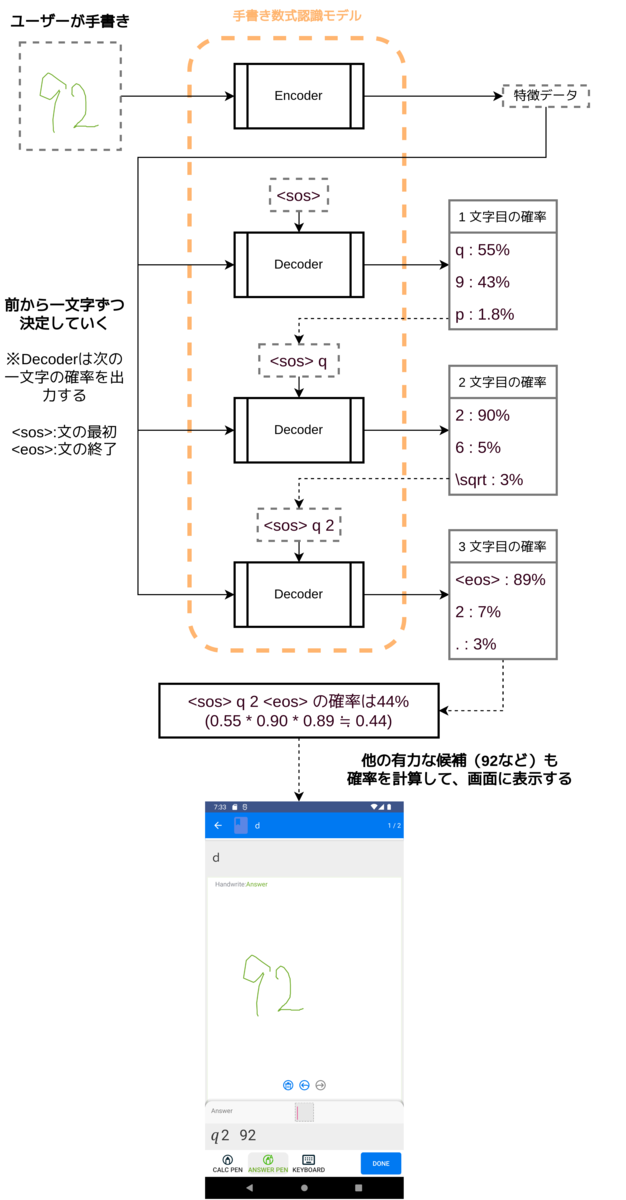
この時点でいくつかの問題が現れていました。
速度の問題
やはりモバイル端末上で問題になるのは、推論の速度です。近年のスマートフォンだとこうした推論を高速化するための専用チップを置いているケースもあり、そういった端末上では問題ありませんが、ユーザー(多くの場合、小中高校生)が使う端末はあまりに様々です。最初のバージョンはミドルレンジな性能のスマートフォンで動かすと、回答を書いてから認識まで数秒待たされるような状況でした。

多くの場合で、まず解決策として挙げられるのは機械学習モデルの量子化ですが、精度の低下がある程度あることと、この後の高速化によって十分な速度になったため棄却しました。いくつか行った改善を紹介します。
推論結果の随時フィードバック
今回の例を含む、一般的なSeq2SeqタスクのTransformerでは、有力な候補をいくつか列挙するためにビームサーチをしています。しかし、
- GPUなどの並列性の高いプロセッサを持たないモバイル端末では、計算時間はビーム幅に敏感(ビーム幅1が絶対早い)
- 多くのケースで貪欲アルゴリズム(ビーム幅1のビームサーチ)の結果はかなり良い
といったことを考え、次の様なアルゴリズムにすることになりました。
- 単純なビームサーチではなく、ビーム幅1のビームサーチを複数回行うことに(いわゆる幅が1のchokudaiサーチ?)
- イテレーションが完了するたびに、随時、探索結果を画面に表示する
この結果、ユーザーの体感でのレスポンスはかなり上昇し、また、ビーム幅というパラメーターを消す事ができました。
前回の探索結果の利用
今回のユースケースでは、ユーザーが入力する一筆ごとに探索が新しく開始されます。ここで、多くのケースでは
- 前回の認識結果と新しい認識結果は、最後の方を除いておおよそ一致していること
が期待できます。
よって
- まず最初にデコーダーに前回の認識結果を与え、今の画像を前提とした時のそれぞれの位置までの確率を求める
→デコーダーは与えた過去の文字列に対して、全ての位置それぞれについて、その位置までの計算してくれる
- それを状態としてchokudaiサーチの状態を管理するヒープに入れる
- 「前回の文字列の長さ+1」の位置から、chokudaiサーチの最初のイテレーションを始める
→末尾に新しく文字を追加したケースだと1回の推論だけで良い解が見つかり、高速
のようにすることで、特に数式が長くなった時に大幅な改善ができました。
枝刈り
chokudaiサーチの一つのイテレーション上でスコアは単調減少になるため、画面上に探索結果をn個しか出さないということが分かっているなら、現在のn番目の探索結果のスコアを下回った時点でそのイテレーションは打ち切ることができます。
これらの高速化の結果、スペックの低い端末上でも十分な速度を確保することができました。最初に挙げた画像の例で、Zenfone2 laserだと改善前は8秒程度認識にかかっていたのが、改善後は書き終えてから1秒未満で候補が表示されるようになりました。
精度の問題
候補の削減
数式認識を実際に触ってみて気づくのは、例えば「c」と書いたつもりで「C」と認識されてしまったり、「w」と「W」、「9」と「q」といったような、似ている文字の認識ミスが無視できない頻度で起こることです。 しかし、解答に「c」を使うような問題で同時に「C」も解答に含まれることはあまりなさそうです。モノグサアプリ側からすれば既に解答は知っていますから、認識する必要がある文字の種類は認識可能な文字の種類よりもとても少ないはずです。そこで、ビームサーチをする際に、解答に登場しない文字は無視することで体感の精度を向上させることができました。
データ拡張
BTTRのリポジトリで提供されていたpretrainedなモデルは既存のデータセットそのままで学習させており、何らかのデータ拡張を行うことで精度向上が狙えそうでした。 データセットは各ストロークが正解ラベル(latex)中の文字に対応づけられており、次の二つの拡張を行いました。
- 数式の部分式だけの切り出し
正解ラベル(latex)中の連続した部分文字列を抜き出し、対応するストロークのみから新しいデータとしました。
例えば
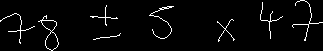
のような式の画像から、
![]()
![]()
![]()
![]()
と言ったデータが作れます。
- 数式中の部分式、文字の変形
変形したい部分のバウンディングボックスにある程度似た、適当な形の四角形を生成し、そこへの射影変換を行いました。
例えば、
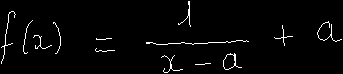
のような式の画像を、↓のように変形します(これは全体を変形する場合。外枠は本来描画されない)
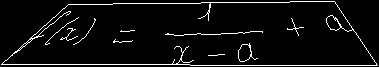
結果、精度は十数パーセント上昇し、大きな改善となりました。
文字に対して手書きのストロークが取ってこれることから、「 latexを与えて、それに対して画像を生成するプログラム」というものも考えましたが
- 実際にありそうな数式のlatexを作成するのが難しい
→完全なランダム生成は現実の数式の分布と大きく異なってしまう
- ルートの記号などの構造をもつ式で、ストロークをうまく組み合わせるのが難しい
といった理由から断念しました。うまく生成できればデータ拡張としてはかなり強力なものになると思っており、今後の課題として残っています。
現在、数式手書き認識は機能公開に向けて開発中です。
春インターンの感想
機械学習モデルをモバイル環境で動かすという課題設定のもとで、その環境をうまく利用するような改善がいくつか出来て大変面白かったです。深層学習の技術に触れること自体も初めてでしたが、今回のインターンを経て、深層学習分野の面白さ、奥深さを知ることができました。大変貴重な経験をさせていただいたモノグサに感謝しています。
モノグサ内には英語学習者の発音の評価や、択一問題での選択肢の自動生成など、機械学習技術が活躍できそうなトピックがいくつも存在しています。今回のモデルのさらなる精度向上も課題です。そういった技術の実世界への適用に興味のある学生(また、現役のエンジニア)の方は是非インターン等の求人に応募してみてください。